Understand the essentials of building a recommendation system with FastAI on Microsoft Fabric. This guide will show you how to implement Collaborative Filtering, a method that powers suggestions by analyzing patterns in user data. As is common in these recommendation system guides, we’ll be using a common Movie Rating dataset. Efficient and straightforward, it’s a practical approach for creating personalized experiences in Microsoft Fabric. Let’s get started.
Inspiration for this article and many of the details on how to get this working are derived from the amazing Practical Deep Learning for Coders course.
Create an ML Model
To start with, create a new ML model in the Data Science section of Microsoft Fabric
You’ll be asked to name your model, as we’ll be recommending movies for users, I’ve creatively named mine Recommender
Next, click on “Start with a new Notebook”
Train your model
The following commands will download a movie recommendation dataset, train a model, and save it with mlflow. Add these to your new Notebook. Each section can be it’s own cell in your notebook.
Install and import requirements
!pip install -U -q fastai recommenders
from fastai.collab import *
from fastai.tabular.all import *
import mlflow
import mlflow.fastai
set_seed(42)
Load a movie ratings dataset from FastAI
path = untar_data(URLs.ML_100k)
!ls {path}
Retrieve the u1.base data which will be used for training and validation.
ratings_df = pd.read_csv(path/'u1.base', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# convert IDs to strings to prevent confusion with embeddings
ratings_df['user'] = ratings_df['user'].astype('str')
ratings_df['movie'] = ratings_df['movie'].astype('str')
ratings_df.head()
Create our dataloader from the ratings dataframe.
data = CollabDataLoaders.from_df(ratings_df,
user_name='user',
item_name='movie',
rating_name='rating',
bs=64)
data.show_batch()
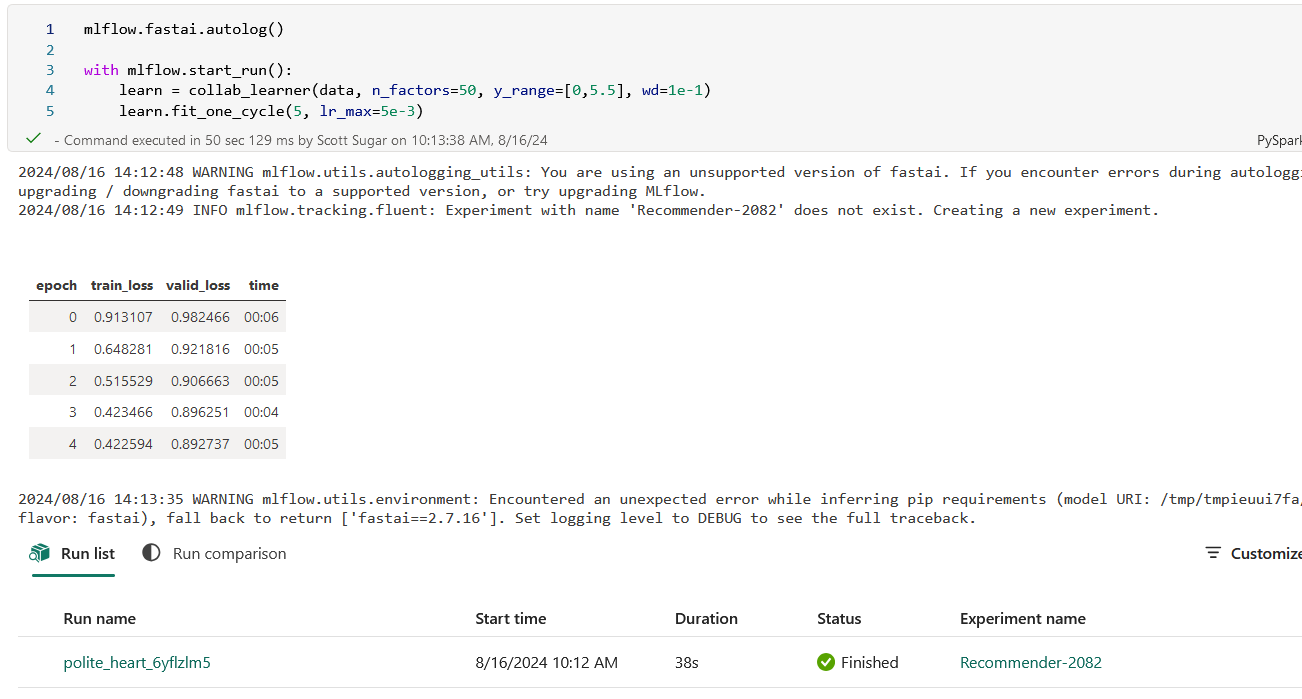
Train our model and save it to mlFlow. Feel free to play with the number of factors, the weight decay, number of epochs and learning rate.
mlflow.fastai.autolog()
with mlflow.start_run():
learn = collab_learner(data, n_factors=50, y_range=[0,5.5], wd=1e-1)
learn.fit_one_cycle(5, lr_max=5e-3)
After running all the above cells, you should see something like this as the output of the final cell:
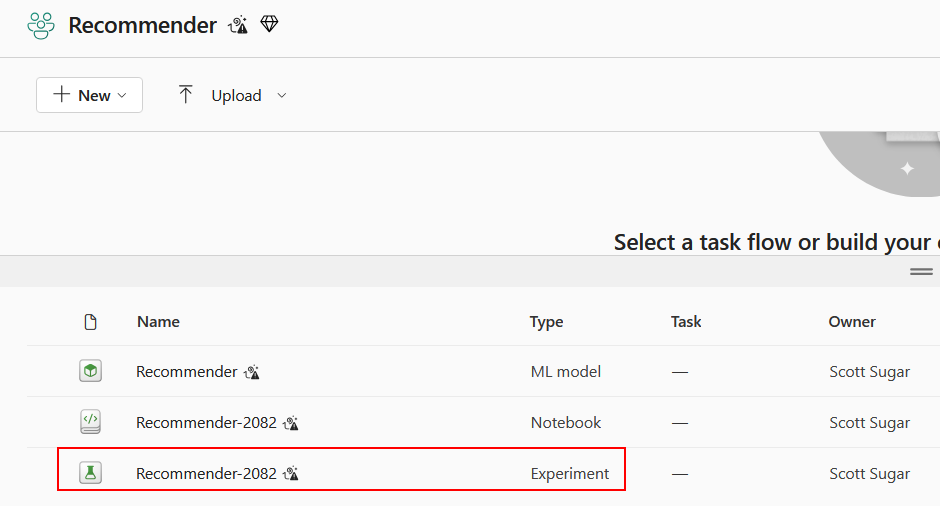
You should also see a new Experiment in your workspace (you may need to refresh your browser window):
Save your ML Model
Open the new experiment that’s been created in your workspace. Click on Save run as ML model
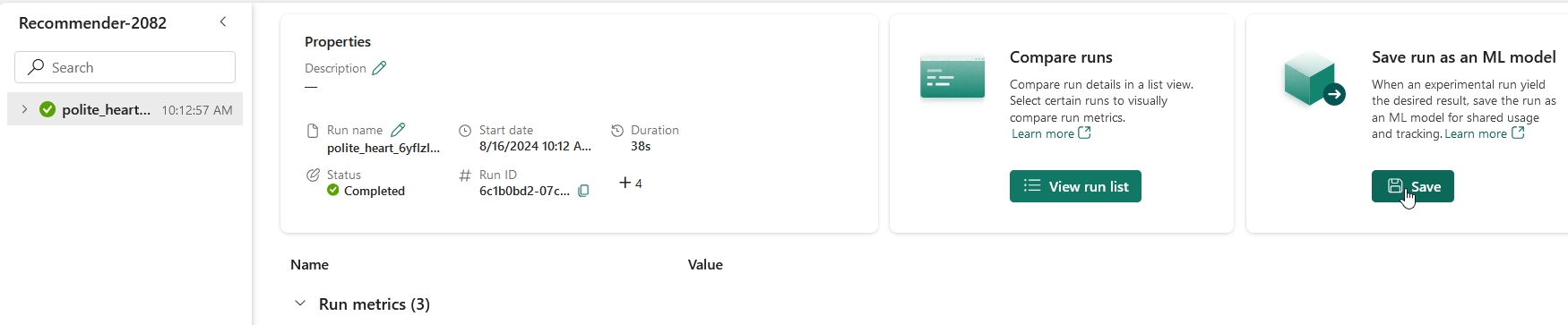
Click on “Select an existing ML model”, select the model folder, select the model you created and click Save.
Load and Predict
Create a new notebook in your workspace. Add the following code to your notebook.
Install and import requirements
!pip install -U -q fastai recommenders
from fastai.tabular.all import *
from recommenders.models.fastai.fastai_utils import score
Next we’re going to load the data again. In this case we’ll load the same data used for training and validation as well as an additional test set of data. We’ll use this data to get a listing of the users that existed in the training and validation data as well as the set of movies that they haven’t seen (i.e. rated) yet. We’re also going to get the names of the movies to make this easier to interpret later.
path = untar_data(URLs.ML_100k)
!ls {path}
Load the movie ids and names in
#read in the movies data for use later
movies = pd.read_csv(path/'u.item', delimiter='|', encoding='latin-1',
usecols=(0,1),
names=('movie','title'),
header=None)
movies['movie'] = movies['movie'].astype('str')
movies.head()
Retrieve the original data we used for training and validation so we can see what the users haven’t seen (i.e. rated) yet.
#retrieve the u1.base data which will be used for training/validation
ratings_df = pd.read_csv(path/'u1.base', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# make sure the IDs are loaded as strings to better prevent confusion with embedding ids
ratings_df['user'] = ratings_df['user'].astype('str')
ratings_df['movie'] = ratings_df['movie'].astype('str')
ratings_df.head()
Read in the testing data set we’ll run predictions on.
#retrieve the u1.test data which will be used for running predictions
test_df = pd.read_csv(path/'u1.test', delimiter='\t', header=None,
names=['user','movie','rating','timestamp'])
# make sure the IDs are loaded as strings to better prevent confusion with embedding ids
test_df['user'] = test_df['user'].astype('str')
test_df['movie'] = test_df['movie'].astype('str')
test_df.head()
Load our saved model
import mlflow
learner = mlflow.fastai.load_model(model_uri=f"models:/Recommender/latest")
Run predictions for the entire test data set
#retrieve all users and items from the dataloader
total_users, total_items = learner.dls.classes.values()
#remove the first element of each array - will be #na, and convert to dataframes
total_users = pd.DataFrame(np.array(total_users[1:], dtype=str), columns=['user'])
total_items = pd.DataFrame(np.array(total_items[1:], dtype=str), columns=['movie'])
#get the unique set of users from the testing data which we will run predictions for
test_users = pd.DataFrame(test_df['user'].unique(), columns=['user'])
#only include users that exist in both the testing and the training dataset (otherwise we will receive an error when scoring/predicting for users that don't exist in the training data).
test_users = test_users.merge(total_users, how='inner')
#build a 2D array that lists all possible items for each test user
users_items = test_users.merge(total_items, how='cross')
#join user_items dataframe back to the original ratings dataframe and only keep items that the user hasn't rated yet (i.e. rating is null)
test_data = pd.merge(users_items, ratings_df.astype(str), on=['user', 'movie'], how='left')
test_data = test_data[test_data['rating'].isna()][['user', 'movie']]
#Score the testing data to retrieve back predictions
top_k_scores = score(learner,
test_df=test_data,
user_col='user',
item_col='movie',
prediction_col='prediction')
#join predictions to movies dataframe to include additional movie information in the prediction (title, genres)
predictions = pd.merge(top_k_scores, movies, left_on='movie', right_on='movie', how='left')
#return all predictions for the test users
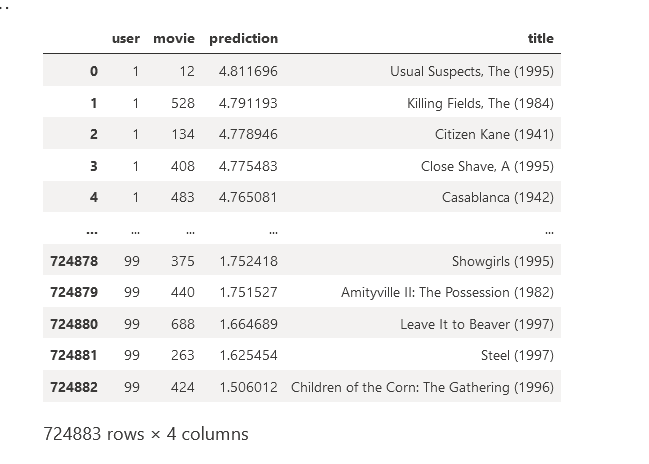
predictions
Result from the notebook should look like this:
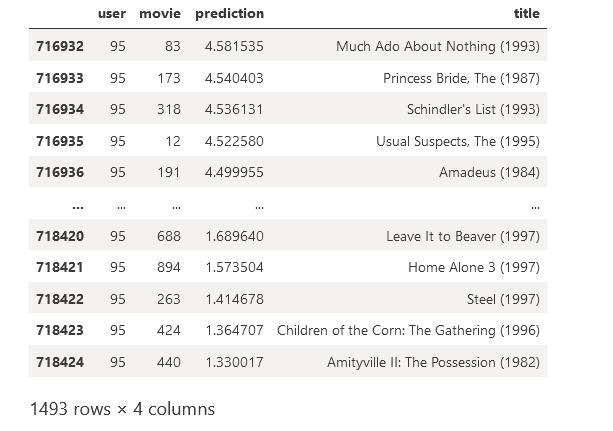
Test predictions for a single user
user = '95'
predictions[predictions['user'] == user]
Conclusion
In conclusion, building a recommendation system with FastAI on Microsoft Fabric is a straightforward process that can significantly enhance user experience by providing personalized content. By following the steps outlined in this guide, you can create a system that not only predicts user preferences but also scales seamlessly with your dataset. With the power of Collaborative Filtering at your fingertips, you’re now equipped to take on the challenge of crafting tailored recommendations that keep users engaged and satisfied.